Datalake Con Minio Y Iceberg
Basandome en este artículo de la documentación oficial de Minio, voy a intentar probar tener un Datalake usando Minio y Iceberg.
Pero primero algunos conceptos.
¿Qué es Iceberg?
Iceberg es un formato de tabla que usa storage y la propia estructura de directorios para armar el catálogo. Digamos que tenemos un data lake storage s3 o adls con la siguiente carpeta:
/warehouse/database/table
donde warehouse sería la ruta del catálogo definido en configuración spark, equivalente a como si fuera un servidor de base de datos, database la base de datos y table la tabla de la base de datos. Si quiera consultar en el catálogo podría usar simple spark SQL de la siguiente forma:
SELECT col1, col2 FROM database.table
en este sentido es un esquema autoorganizado. Pero hay más, Iceberg ofrece versionamiento, evolución de esquema y no es necesario definir índices ya que los crea el mismo. Esto es gracias a su estructura que aprovecha el mismo storage y logs.
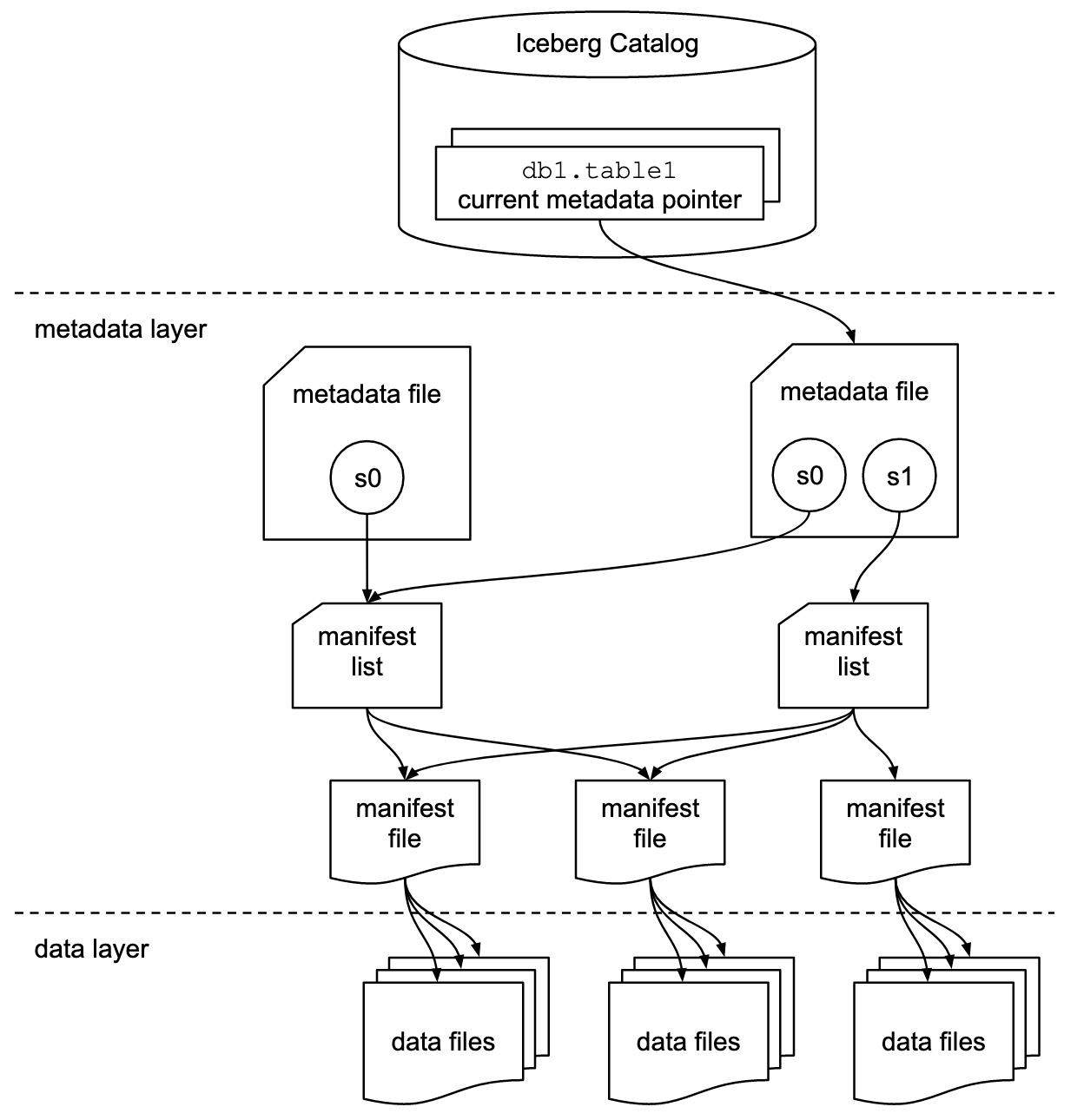
Click en imagen para abrir más grande en nueva pestaña
¿Qué es Minio?
Minio es un object storage compatible con el API de Amazon S3, se puede usar la misma api para la creación, actualización, modificación y eliminación de objetos y al ser open este permite tener su propio storage. Provee una interfaz web donde se pueden ver los objetos así como usar las mismas tools de las apis compatibles S3 y por lo tanto es compatible también con Spark.
Ejecución y revisión de datalake
Procedemos a importar el docker compose del artículo al equipo local y desde la ruta que lo guardamos lo ejecutamos con docker-compose up:

Click en imagen para abrir más grande en nueva pestaña
al ejecutar aparece una URL local al notebook jupyter:

Click en imagen para abrir más grande en nueva pestaña
vamos al notebook y se ve que este viene con varios ejemplos:
Click en imagen para abrir más grande en nueva pestaña
nos vamos al notebook Getting Started y ejecutamos hasta el SQL que crea una base de datos, una tabla y carga datos de un parquet a la tabla:
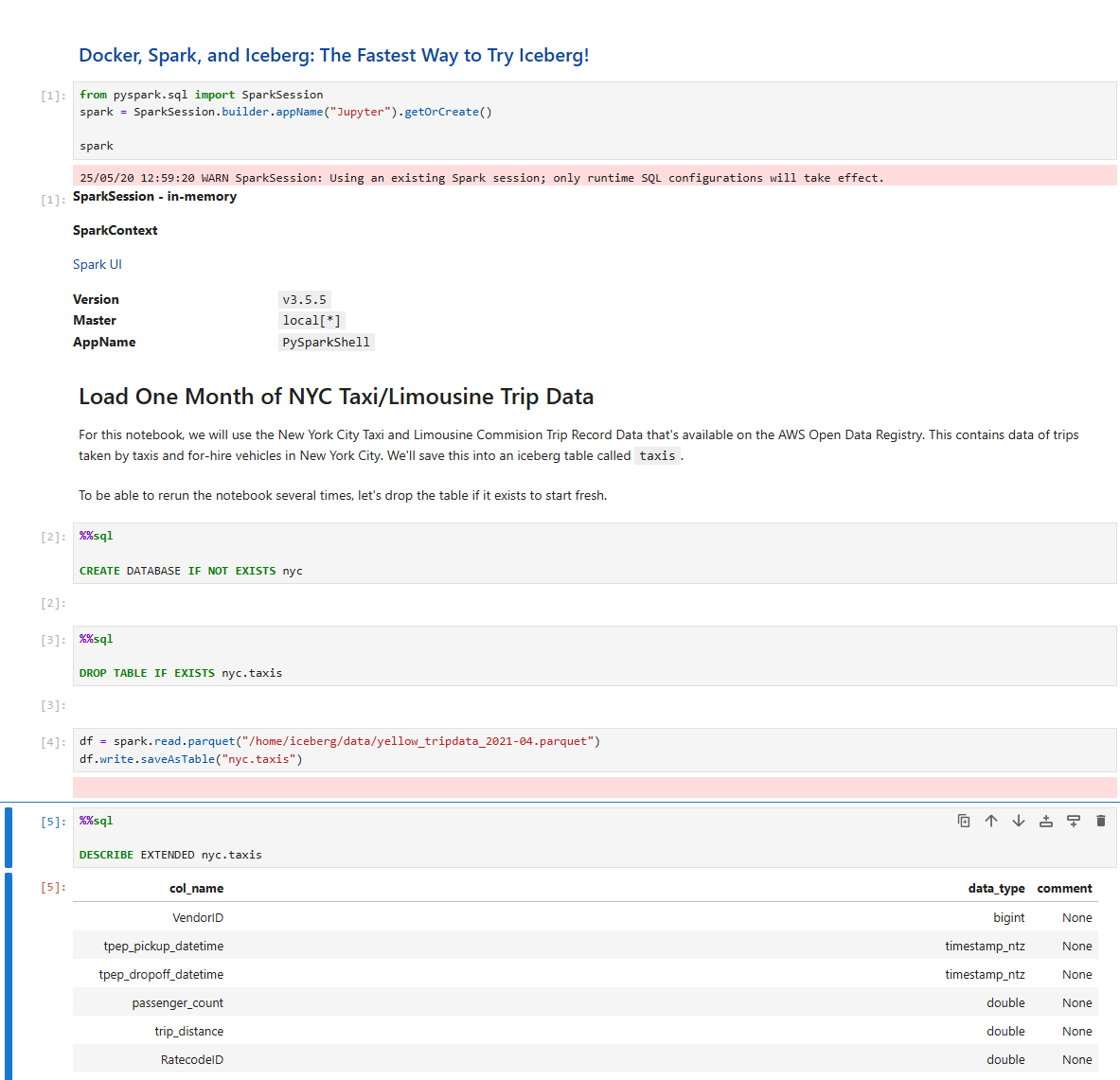
Click en imagen para abrir más grande en nueva pestaña
luego nos vamos a la interfaz de Minio, esta se entra en http://localhost:9001/, el usuario y password se ve en el archivo docker-compose.
Click en imagen para abrir más grande en nueva pestaña
entramos a la ruta warehouse y podemos ver que se crea la carpeta de la base de datos nyc y la tabla taxis, finalmente al entrar están las dos carpetas de metadata y data.
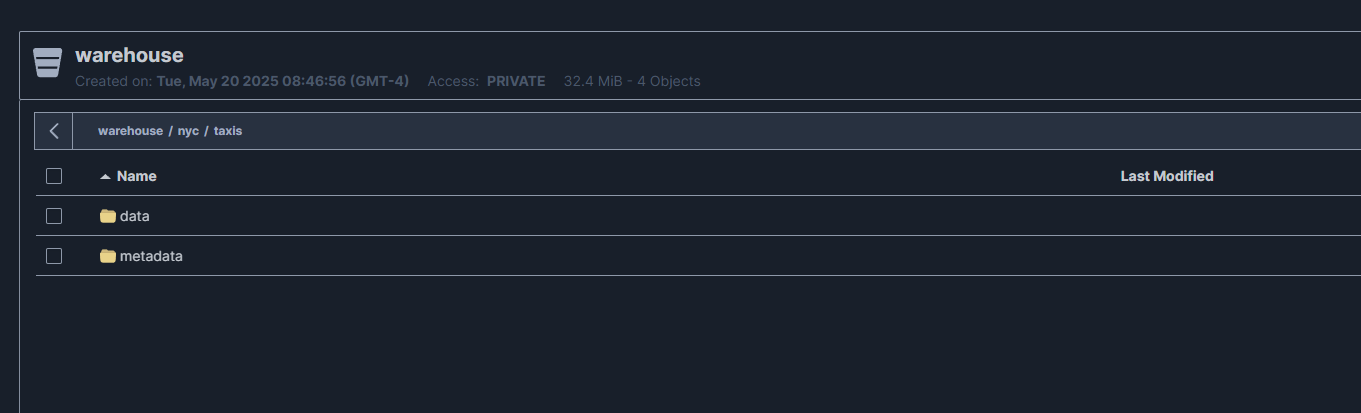
Click en imagen para abrir más grande en nueva pestaña
en la carpeta data se puede ver archivos parquet de la tabla, como se insertó una vez solo se ve uno, pero a medida que se agreguen aparecerán más.
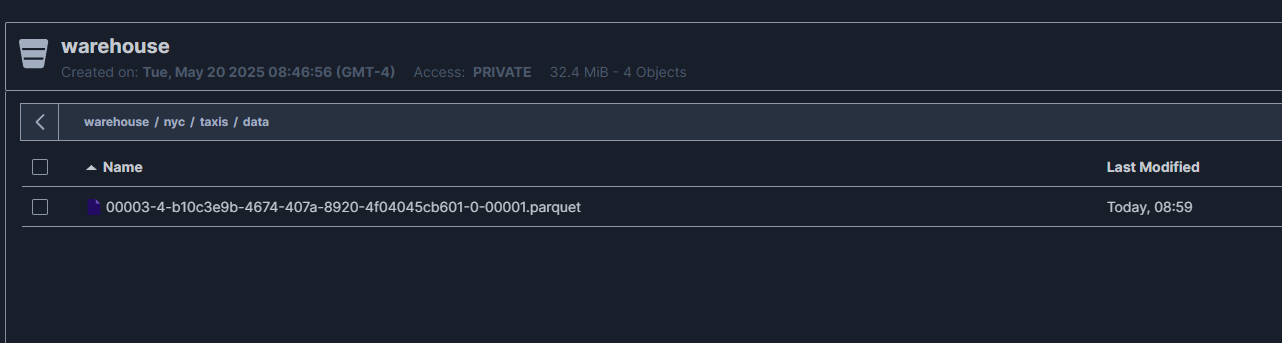
Click en imagen para abrir más grande en nueva pestaña
y en la carpeta metadata está el log de la tabla en que mezcla archivos json y avro
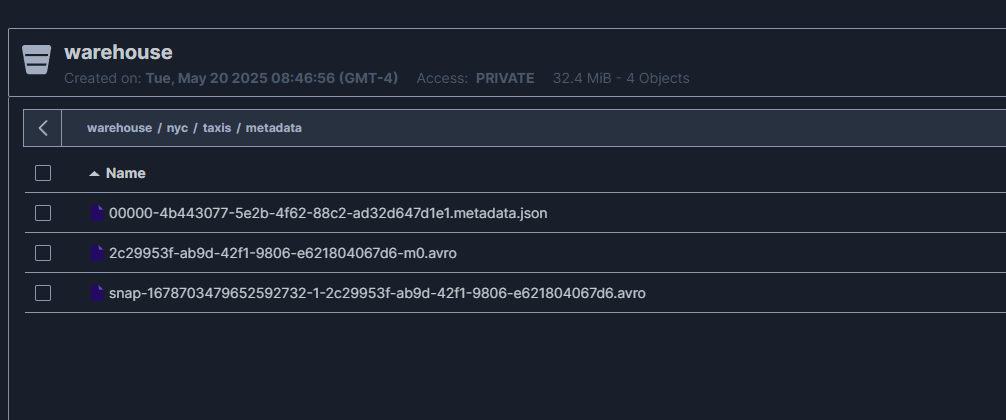
Click en imagen para abrir más grande en nueva pestaña
finalmente revisamos el archivo json con la metadata
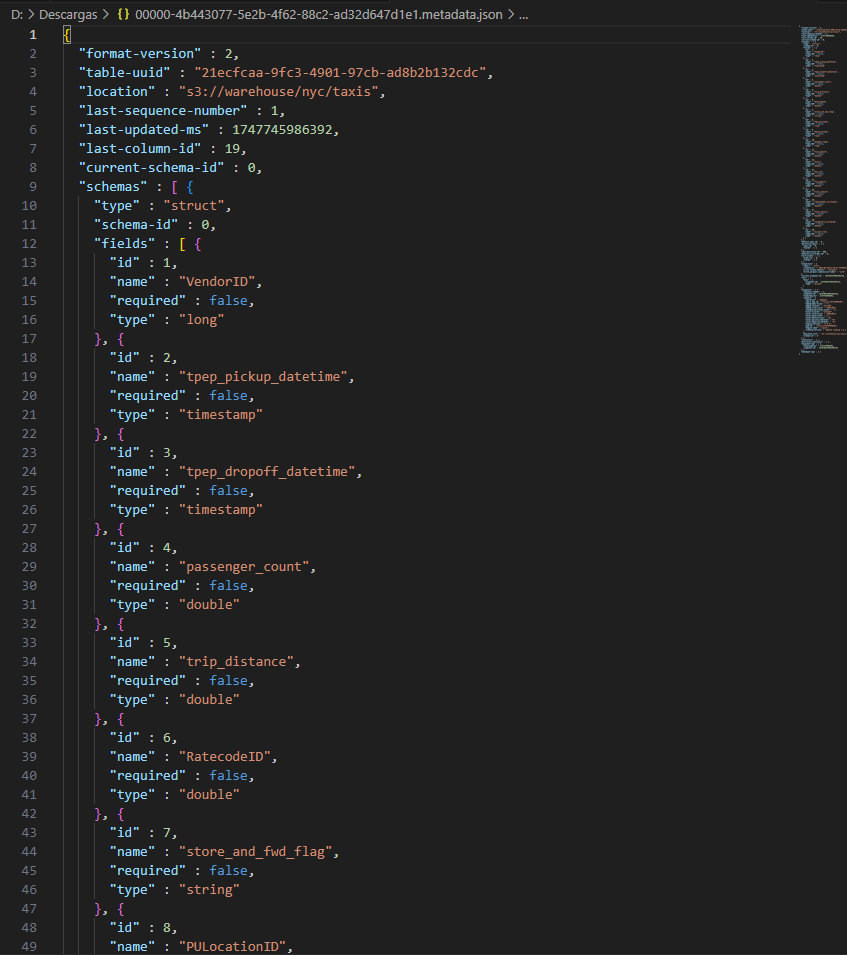
Click en imagen para abrir más grande en nueva pestaña
El notebook getting started tiene harta información sobre como ingestar datos, modificar tablas. También en los mismos notebooks hay ejemplo para consultar via DuckDB con PyIceberg y también escribir tablas sin necesidad de tener PySpark.
Espero que esta info les sea muy útil. Nos leemos!!